Goals/Context
-
no broad tests are required. The test suite consists of “narrow” tests focused on specific concepts. Although wide integration tests can be added as a safety net, their failure indicates a gap in the main test suite
-
easy refactoring
-
no magic. Tools that automatically remove busywork, such as dependency-injection and auto-mock frameworks, are not required.
-
Not a silver bullet. Design mistakes are inevitable, requiring continuous attention to design and refactoring.
-
benefits from learning to listen to test smell
- keep knowledge local. The “magic” need to create mocks could cause the knowledge to leak between components.
- if we can keep knowledge local to an object (either internal or passed in), then its implementation is independent of its context. So we can safely move it where we like.
- Do this consistently, and your application, built out of pluggable components, will be easy to change.
- If it’s explicit, we can name it
- Avoid mocking concrete classes that can help us give names to the relationships between objects and the objects themselves.
- As the legends say, if we have something’s true name, we can control it.
- if we can see it, we have a better chance of finding its other uses and reducing duplication.
- more names mean more domain information
- we find that when we emphasize how objects communicate rather than what they are, we end up with types and roles defined more in terms of domain than the implementation.
- we seem to get more domain vocabulary into the code
- This might be because we have a more significant number of smaller abstractions, which gets us further away from the underlying language.
- pass behaviour rather than data
- we find that by applying “Tell, Don’t Ask” consistently, we end up with a coding style where we tend to pass behaviour (in the form of callbacks) into the system instead of pulling values up through the call stack.
- this keeps the tests and the code clean as we go. It helps to ensure that we understand our domain and reduces the risk of being unable to cope when a new requirement triggers changes to the design.
- a unit test shouldn’t be 1000 lines long! It should focus on at most a few classes and should not need to create a large fixture or perform lots of preparation to get the objects into a state where the target feature can be exercised.
- keep knowledge local. The “magic” need to create mocks could cause the knowledge to leak between components.
-
from xUnit patterns
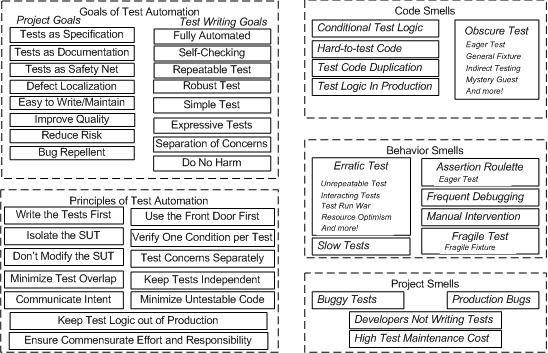
Test Pain Points
- Obscure Tests
- confuse the differences between test cases
- single test case exercises multiple features
- can’t skim-read the tests to understand the intention
- uses magic numbers but are not clear about what, if anything, is significant about those values
- tests with lots of code for setting up and handling exceptions, which buries their essential logic.
- mocking values
- mock value object means that we want to describe the behaviour of the interface explicitly, and we can’t think of a name for the concrete implementation of the interface/class
- when there isn’t a good implementation name. It might mean that the interface is poorly named or designed. Perhaps it’s unfocused because it has too many responsibilities, or it’s named after its implementation rather than its role in the client
- it’s a value, not an object.
- If you’re tempted to mock a value because it’s too complicated to set up an instance, consider writing a builder.
- partial mocks
- test diagnostics
- mocking concrete classes
- avoid override behaviour in testable subclass
- it leaves the relationship between objects implicit.
- If we subclass, there’s nothing in the domain code to make such a relationship visible - just methods on an object. This makes it hard to see if the service that supports this relationship might be relevant elsewhere, and we’ll have to do the analysis again next time we work with the class.
- When we mock a concrete class, we force client objects to depend on interfaces they do not use.
- Instead, extract an interface as part of our test-driven development process. It will push us to think up a name to describe the relationship we’ve just discovered. This makes us think harder about the domain and teases out concepts we might otherwise miss.
- If you can’t get/access the structure you need, the tests tell you that it’s time to break up the class into more minor, composable features.
- avoid override behaviour in testable subclass
- bloated constructor
- Some arguments define a concept that should be packaged up and replaced with a new object to represent it.
- Being sensitive to complexity in the tests can help us clarify our designs.
- Look for arguments always used together in a class and those with the same lifetime. Give it a good name to explain the concept.
- Confused object
- too large because it has too many responsibilities.
- it would likely has a bloated constructor
- another associated smell is that its test suite will look confused. The tests for its various features will have no relationship with each other. We cannot make significant changes in one area without touching others.
- too many dependencies
- dependencies should be passed into the constructor, but notifications and adjustments can be set to defaults and reconfigured later.
- Initialized the peers to standard defaults, the user can configure them later through the user interface, and we can configure them in our unit tests.
- too many expectations
- we can’t tell what’s significant and what’s just there to get through the test
- we can make our intentions clearer by distinguishing between stubs simulations of actual behaviour that help us get the test to pass and expectations, assertions we want to make about how an object interacts with its neighbours.
- allow queries and expect commands
- commands are calls that are likely to have side effects, to change the world outside the target object. queries don’t change the world, so they can be called any number of times, including none
- the rule helps to decouple the test from the tested object. So if the implementation changes, for example, to introduce caching or use a different algorithm, the test is still valid.
- Many expectations indicate that we’re trying to test too large a unit or locking down too many of the object’s interactions.
- constructing complex test data
- testing persistence
- tests with threads
- testing asynchronous code
- seeding DB data everywhere
- magic injection of objects and data
- overlapping sociable tests (constructing entire dependency chain)
- test brittleness
- the tests are too tightly coupled to unrelated parts of the system or irrelevant behaviour of the object(s) they’re testing
- tests overspecify the expected behaviour of the target code, constraining it more than necessary.
- there is duplication when multiple tests exercise the same production code behaviour
- beware of flickering tests
- a test can fail intermittently if its timeout is too close to the time the tested behaviour typically takes to run or if it doesn’t synchronize correctly with the system.
- flickering tests can mask actual defects. We need to make sure that we understand what the real problem is before we ignore flickering tests
- allow flickering tests is terrible for the team. It breaks the quality culture where things should “just work,” Even a few flickering tests can make the team stop paying attention to broken builds.
- it also breaks the habits of feedback.
- we should be paying attention to why the tests are flickering and whether that means improving the design of both the tests and code.
- runaway tests
- be careful when an asynchronous test asserts that the system returns to a previous state.
- unless it also asserts that the system enters an intermediate state before asserting the initial state, the test will run ahead of the system.
send(aTradeEvent().ofType(BUY).onDate(tradeDate).forStock("A").withQuantity(10));
assertEventually(holdingOfStock("A", tradeDate, equalTo(10)));
send(aTradeEvent().ofType(SELL).onDate(tradeDate).forStock("A").withQuantity(10));
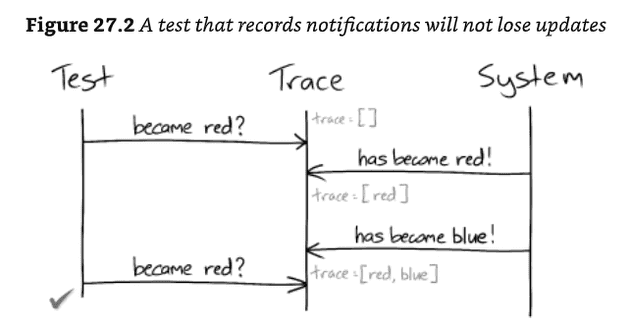
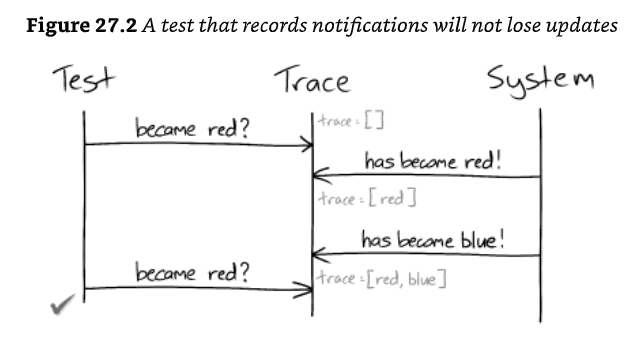
assertEventually(holdingOfStock("A", tradeDate, equalTo(10)));- lost updates
- a significant difference between tests that sample and those that listen for events is that polling can miss state changes that are later overwritten
- if the test can record notifications from the system, it can look through its records to find essential notifications.
- to be reliable, a sampling test must ensure that its system is stable before triggering any further interactions.
-
-
Test Patterns
Tests readability
- avoid irrelevant information and make the cause-effect relationship between the fixture and verification logic clear
- test names describe features (high-level languages and abstractions)
- think of one coherent feature per test, which might be represented by up to a handful of assertions.
- If a single test seems to be making assertions about different features of a target object, it might be worth splitting up.
- a common approach is to name a test after the method it’s exercising
- at best, such names duplicate the information a developer could get just by looking at the target class
- we don’t need to know that TargetObject has a “choose” method, we need to know what the object does in different situations, what the method is for
- a better alternative is to name tests in terms of the target object’s features.
- TestDox convention: Each test name reads like a sentence, with the target class as the implicit subject.
- a List holds items in the other they were added: holdsItemsInTheOrderTheyWereAdded
- the point of the convention is to encourage the developer to think about what the target object does, not what it is.
- TestDox convention: Each test name reads like a sentence, with the target class as the implicit subject.
- When writing the tests, some developers start with the test name first, and some begin to create a placeholder for the test names before writing any test codes. Both approaches work as long as the test is, in the end, consistent and expressive.
- read documentation generated from tests (provide a fresh perspective on the test names, highlighting the problems we’re too close to the code to see)
- arrange/act/assert structure is not clear
- write in order: test names/act/assert/arrange to help us focus on what to write and avoid being coupled to the low technical implementation details
- emphasize the what over the how.
- the more implementation detail is included in a test method, the harder it is for the reader to understand what’s important.
- use structure to explain and share
- jMock syntaxes are designed to allow developers to compose small features into a (more or less) readable description of an assertion.
- be careful in factoring out test structure, where the test becomes so abstract that we cannot see what it does anymore.
- our most significant concern is making the test describe what the target code does, so we refactor enough to see its flow.
- accentuate the positive. Only catch exceptions in a test if we want to assert something about them.
- delegate to subordinate objects as mentioned in the programming by intention
- assertions and expectations
- the assertions and expectations of a test should communicate precisely what matters in the behaviour of the target code.
- Avoid magic numbers with no clear cause-effect relationship.
- literal values without explanation can be difficult to understand because the programmer has to interpret whether a particular value is significant or just an arbitrary placeholder to trace behaviour (e.g. should be doubled and passed on to a peer).
- allocate literal values to variables and constants with names that describe their function.
removing duplication
- remove duplication at the point of use
- change tests’ emphasis to what behaviour expected, rather than how the test is implemented.
- extract some of the behaviour into builder objects and end up with a declarative description of what the feature does.
- we’re nudging the test code towards the sort of language we could use when discussing the feature with someone else, even someone non-technical.
- we push everything else into supporting code.
- describe the intention of a feature, not just a sequence of steps to drive it.
- using these techniques, we can use higher-level tests to communicate directly with non-technical stakeholders, such as business analysts. We can use the tests to help us narrow down exactly what a feature should do and why.
- other tools are designed to foster collaboration across the technical and non-technical members of a team, such as FIT, Cucumber.
- avoid reasserting behaviour that is covered in other tests
test diagnostics
- design to fail informatively: the point of a test is not to pass but to fail. If a failing test clearly explains what has failed and why we can quickly diagnose and correct the code.
- we want to avoid situations when we can’t diagnose a test failure that has happened. The last thing we should have to do is crack open the debugger and step through the tested code to find the point of disagreement.
- not too inhibited about dropping code and trying again. Sometimes, it’s quicker to roll back and restart with a clear head than to keep digging
- if the test is small, focused and has readable names, it should tell us most of what we need to know about what has gone wrong.
- explanatory assertion messages
- the failure message should describe the cause rather than the symptom.
- highlight details with matchers. In addition, the matcher API includes support for describing the mismatched value to help with understanding precisely what is different.
- self-describing value: build the detail into values in the assertion. If we add detail to an assertion, maybe that’s a hint that we could make the failure more obvious.
expected: <a customer account id> but was <id not set>
use new Date(timeValue) {public String toString() {return name; })
expected: <startDate>, got <endDate>- obvious canned value
- conventions for common values can ensure that it stands out
- tracer object
- dummy object that has no supported behaviour of its own, except to describe its role when something fails.
- Jmock can accept a name when creating a mock object that will be used in failure reporting. However, where there’s more than one mock object of the same type, jMock insists that they are named to avoid confusion.
- explicitly assert that the expectation was satisfied.
- A test with both expectations and assertions can produce a confusing failure. For example, this would create a failure report that says an incorrect calculation result rather than the missing collaboration that caused it.
- it’s essential to watch the test fails.
- it might be worth calling the assertIsSatisfied before any test assertions to get the right failure report.
- diagnostics are a first-class feature: try to follow four steps TDD cycle (fail, report (make the diagnostics clear), pass, refactor)
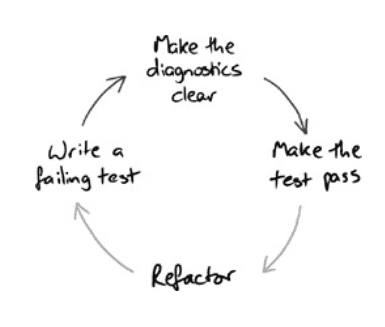
test for information, not a representation
- if the test is structured in terms of how other parts of the system represent the value, then it has a dependency on those parts and will break when they change.
- For example, mock the collaborator to return null if there’s no customer found.
- first, we need to remember what’s null means
- better, we could represent null with Maybe
- if, instead, we’d given the tests their representation of “no customer found” as a single well-named constant instead of the literal null.
- tests should be written in terms of the information passed between objects, not of how that information is represented.
- it will make the tests more self-explanatory and shield them from changes in implementation controlled elsewhere in the system.
precise assertions
- focus the assertions on just what’s relevant to the scenario being tested
- avoid asserting values that aren’t driven by the test inputs,
- avoid reasserting the behaviour that is covered in other tests
- testing for equality doesn’t scale well as the returned value becomes more complex. At the same time, comparing the total result each time is misleading and introduces an implicit dependency on the behaviour.
unit testing and threads
- unit tests give us confidence that an object performs its synchronization responsibilities, such as locking its state or blocking and walking threads.
- coarser-grained tests, such as system tests, give us confidence that the entire system manages concurrency correctly.
- limitations of unit stress tests
- it is challenging to diagnose race conditions with a debugger, as stepping through code (or even adding print statements) will alter the thread scheduling causing the clash.
- there may be scheduling differences between different os and processor combinations. Further, there may be other processes on a host that affect scheduling while the tests are running.
- run unit tests to check that our objects correctly synchronize concurrent threads and pinpoint synchronization failures.
- run end-to-end tests to check that unit-level synchronization policies integrate across the entire system.
- it is challenging to diagnose race conditions with a debugger, as stepping through code (or even adding print statements) will alter the thread scheduling causing the clash.
separating functionality and concurrency policy
- auction search is complicated because it needs to implement the search and notification functionality and the synchronization at the same time
- we want to separate the logic that splits a request into multiple tasks from the technical details of how those tasks are executed concurrently. So we pass a “task runner” into the AuctionSearch, which can then delegate managing tasks to the runner instead of starting threads itself.
- concurrency is a system-wide concern that should be controlled outside the objects that need concurrent tasks.
- the application can now easily adapt the object to the application’s threading policy without changing its implementation (“context independence” design principle)
- We need to run the tasks in the same thread as the test runner for testing instead of creating new task threads.
@Test
public void searchesAuctionHouses() throws Exception {
Set<String> keywords = set("sheep", "cheese");
auctionHouseA.willReturnSearchResults(keywords, resultsFromA);
auctionHouseB.willReturnSearchResults(keywords, resultsFromB);
context.checking(new Expectations() {{
States searching = context.states("activity");
oneOf(consumer).auctionSearchFound(resultsFromA);
when(searching.isNot("finished"));
oneOf(consumer).auctionSearchFound(resultsFromB);
when(searching.isNot("finished"));
oneOf(consumer).auctionSearchFinished();
then(searching.is("finished"));
}});
search.search(keywords);
executor.runUntilIdle();
}- design stress test regard to aspects of an object’s observable behaviour that are independent of the number of threads calling into the object (observable invariants concerning concurrency)
- write a stress test for the invariant that exercises the object multiple times from multiple threads
- watch the test fail, and tune the stress test until it reliably fails on every test run; and,
- make test the test pass by adding synchronization
- For example, one invariant of our auctionSearch is that it notifies the consumer just once the search has finished, no matter how many Auction houses it searches or how many threads it starts.
// Change to v2, v3, v4 to test different versions...
AuctionSearch_v4 search = new AuctionSearch_v4(executor, auctionHouses(), consumer);
@Test(timeout = 500)
public void
onlyOneAuctionSearchFinishedNotificationPerSearch() throws InterruptedException {
context.checking(new Expectations() {{
ignoring(consumer).auctionSearchFound(with(anyResults()));
}});
for (int i = 0; i < NUMBER_OF_SEARCHES; i++) {
completeASearch();
}
}
private void completeASearch() throws InterruptedException {
searching.startsAs("in progress");
context.checking(new Expectations() {{
exactly(1).of(consumer).auctionSearchFinished();
then(searching.is("done"));
}});
search.search(KEYWORDS);
synchroniser.waitUntil(searching.is("done"));
}- stress testing passive objects
- most objects don’t start threads themselves but have multiple threads “pass-through” them and alter their state. In such cases, an object must synchronize access to any state that might cause a race condition
- to stress-test the synchronization of a passive object, the test must start its threads to call the object. When all the threads have finished, the object’s state should be the same as if those calls had happened in sequence.
- synchronizing test thread with background threads
- avoid sleep/delay
- use jMock’s Synchroniser for synchronizing between test and background threads, based on whether a state machine has entered or left a given state
synchroniser.waitUtil(searching.is("finished"))
synchroniser.waitUtil(searching.isNot("inprogress"))Testing asynchronous code
- in an asynchronous test, the control returns to the test before the tested activity is complete.
- An asynchronous test must wait for success and use timeouts to detect failure.
- this implies every tested activity must have an observable effect: a test must affect the system so that its observable state becomes different.
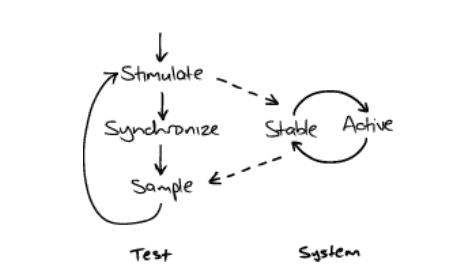
- there are two ways a test can observe the system: by sampling its observable state or listening for events that it sends out.
- for example, auction sniper end-to-end tests sample the user interface for display changes through the window licker framework but listen for chat events in the fake auction server.
- make asynchronous tests detect success as quickly as possible to provide rapid feedback.
- put the timeout values in one place
- there’s a balance to be struck between a timeout that’s too short, which will make the tests unreliable, and one that’s too long, which will make failing tests too slow
- when the timeout duration is defined in one place, it’s easy to find and change.
- scattering Adhoc sleeps and timeouts throughout the tests makes them challenging to understand because it leaves too much implementation detail in the tests themselves.
- capturing notifications
- an event-based assertion waits for an event by blocking a monitor until it gets notified or times out. When the monitor is notified, the test thread wakes up and finds that the scheduled event has arrived or is blocked again. If the test times out, then it raises a failure.
public class NotificationTrace<T> {
private final Object traceLock = new Object();
private final List<T> trace = new ArrayList<T>();
private long timeoutMs = 1000L;
public void append(T message) {
synchronized (traceLock) {
trace.add(message);
traceLock.notifyAll();
}
}
public void containsNotification(Matcher<? super T> criteria)
throws InterruptedException {
Timeout timeout = new Timeout(timeoutMs);
synchronized (traceLock) {
NotificationStream<T> stream = new NotificationStream<T>(trace, criteria);
while (!stream.hasMatched()) {
if (timeout.hasTimedOut()) {
throw new AssertionError(failureDescriptionFrom(criteria));
}
timeout.waitOn(traceLock);
}
}
}
private String failureDescriptionFrom(Matcher<? super T> acceptanceCriteria) {
// construct a description of why there was no match
// including the matcher and all the received messages.
}
public static class NotificationStream<N> {
private final List<N> notifications;
private final Matcher<? super N> criteria;
private int next = 0;
public boolean hasMatched() {
while (next < notifications.size()) {
if (criteria.matches(notifications.get(next)))
return true;
next++;
}
return false;
}
}
} NotificationTrace<String> trace = new NotificationTrace<String>();
@Test(timeout = 500)
public void waitsForMatchingMessage() throws InterruptedException {
scheduler.schedule(new Runnable() {
public void run() {
trace.append("WANTED");
}
}, 100, TimeUnit.MILLISECONDS);
trace.containsNotification(equalTo("WANTED"));
}
@Test
public void failsIfNoMatchingMessageReceived() throws InterruptedException {
try {
trace.containsNotification(equalTo("WANTED"));
} catch (AssertionError e) {
assertThat("error message includes trace of messages received before failure",
e.getMessage(), containsString("NOT-WANTED"));
return;
}
fail("should have thrown AssertionError");
}- polling for changes
- A sample-based assertion repeatedly samples some visible effect of the system through a “probe,” waiting for the probe to detect that the system has entered an expected state.
- there are two aspects to the process of sampling: polling the system and failure reporting and probing the system for a given state.
assertEventually(fileLength("data.txt", is(greaterThan(2000))))
....
public static void assertEventually(Probe probe) throws InterruptedException{
new Poller(1000L, 100L).check(probe))
}
...
public static Probe fileLength(String path, final Matcher<Integer> matcher) {
final File file = new File(path);
return new Probe() {
private long lastFileLength = NOT_SET;
public void sample() {
lastFileLength = file.length();
}
public boolean isSatisfied() {
return lastFileLength != NOT_SET && matcher.matches(lastFileLength);
}
};
}- timing out
@Test
public void reportsIfTimedOut() throws InterruptedException {
Timeout timeout = new Timeout(100);
assertTrue("should not have timed out", !timeout.hasTimedOut());
Thread.sleep(100);
assertTrue("should have timed out", timeout.hasTimedOut());
}
@Test(timeout = 300)
public void waitsForTimeout() throws InterruptedException {
final Object lock = new Object();
long start = System.currentTimeMillis();
Timeout timeout = new Timeout(250);
synchronized (lock) {
timeout.waitOn(lock);
}
long woken = System.currentTimeMillis();
assertTrue("should have waited until the timeout", (woken - start) >= 250);
}- testing that an action has no effect
- if an asynchronous test waits for something not to happen, it cannot even be sure that the system has started before it checks the result.
- the test should trigger behaviour that is detectable and use that to detect that the system has stabilized
- the skill here is in picking behaviour that will not interfere with the test’s assertions and will complete after the tested behaviour.
- distinguish synchronizations and assertions
- adopt a naming scheme to distinguish between synchronizations and assertions. For example, waitUntil() and assertEventually()
- externalize event sources
- hidden timers are complicated to work with because they make it hard to tell when the system is in a stable state for a test to make its assertions
- the only solution is to make the system deterministic by decoupling it from its scheduling.
- we can pull event generation out into a shared service-driven externally.
- i.e., the system’s scheduler as a web service. System components schedule activities by making HTTP requests to the scheduler, triggering actions by making HTTP “postbacks.”
- i.e., the scheduler published notifications onto a message bus topic that the components listened to.
- we can pull event generation out into a shared service-driven externally.
- usually, introducing such an event infrastructure turns out to be useful for monitoring and administration.
- the trade-off is that our tests no longer exercise the entire system. We could also write a few slow tests, running in a separate build, that combine the whole design, including the real scheduler.
Object mother pattern
- contains several factory methods that create objects for use in tests.
- The mother object makes the test more readable by packaging up the code that creates new object structures and gives it a name.
- does not cope well with variation in the test data - every minor difference requires a new factory method.
Test data builders
- most often used for values
- the builder has “chainable” public methods for overwriting the values in its fields and, by convention, a build() method that is called last to create a new instance of the target object from the field values.
- tests that need particular values within an object can specify just those values that are relevant and use defaults for the rest.
- keep tests expressive and resilient to change
- wrap up most of the syntax noise when creating new objects
- make the default case simple, and special cases not much more complicated.
- it protects the test against the changes in the structure of its object (like adding a new argument to the constructor)
- it helps easier to spot the errors because each builder method identifies the purpose of its parameter. (like new AddressBuilder().withStreet2(), make it obvious that street2 is passed in)
- create similar objects
- we can initialize a single builder with the common state and then, for each object to be built, define the differing values and call its build() method
- combining builders
- emphasizes the important information, what is being built, rather than the mechanics of building it.
- passing around the builders can remove much of the noise of calling build method.
- anOrder().fromCustomer(aCustomer().withAddress(anAddress().withNoPostcode()))).build()
to break hard-to-mock dependencies
- make dependencies explicit (by injecting it through constructor)
- singletons (such as Date())
- extract method related to that implicit dependencies and maybe move that behaviour to the implicit dependency
- the object should not have any getter/setter. Whenever you see a piece of code that uses the getter/setter, you might want to consider moving that piece of code to the object.
Domain oriented observability
- support logging: the messages are intended to be tracked by support staff and perhaps system administrators and operators to diagnose a failure or monitor the progress of the running system.
- Diagnostic logging (debug and trace) is infrastructure for programmers. These messages should not be turned on in production because they’re intended to help the programmers understand what’s happening inside the system they’re developing.
- domain probe: enables us to add observability to the domain logic while still talking in the language of the domain
- this.instrumentation.addingProductToCart({productId})
- support.notifyFiltering(tracker, location, filter);
- we’re writing code in terms of our intent (helping the support people, instrumentation) rather than implementation (logging), so it’s more expressive.
A-Frame Architecture
- it’s easiest to test code that doesn’t depend on Infrastructure (external systems such as databases, file systems, and services). However, a typical layered architecture puts infrastructure at the bottom of the dependency chain: Application/UI -> Logic -> infrastructure
- Therefore, structure your application so that Infrastructure and Logic are peers under the application layer, with no dependencies between Infrastructure and Logic.
infrastructure <- application/UI -> logic
- Logic sandwich
- The infrastructure and logic layers can’t communicate with each other.
- infrastructure.writeData(logic.processInput(infrastructure.readData()))
- traffic cop
- use observer pattern to send events from infrastructure to the application layer.
- Be careful not to let your traffic cop turn into a god class.
- Moving some logic code into the infrastructure layer can simplify the overall design.
- splitting the application layer into multiple classes, each with its own Logic Sandwich or simple traffic cop, can help
Climb the ladder
- when logic code has infrastructure dependencies. The code will be difficult to test or resist refactoring
- refactor problem code into a miniature A-Frame architecture. Start at the lowest levels of your logic layer and choose a single method that depends on one clearly-defined piece of infrastructure.
- If the infrastructure code is intertwingled with the Logic code, dis-intertwingled it by factoring out an infrastructure wrapper.
- The method will act similarly to an application layer class: it will have a mix of logic and calls to infrastructure. Make this code easier to refactor by rewriting its tests to use Nullable Infrastructure dependencies instead of mocks. Then factor all the logic code into methods with no infrastructure dependencies.
- At this point, your original method will have nothing left but a small “Logic Sandwich: a call or 2 to the infrastructure class and a call to the new logic method. Now eliminate the original method by inlining it to its callers’. This will cause the logic sandwich to climb one step up your dependency chain.
- At that point, review its design and refactor as desired to better fit the “Logic Patterns” and your application’s needs.
- Climbing the ladder takes a lot of time and effort, so do it gradually, as part of your regular work, rather than all at once.
- Focus your efforts on code where testing without mocks will have noticeable benefits. Don’t waste time refactoring code that’s already easy to maintain, regardless of whether it uses mocks.
Easily visible behaviour
- logic layer computation can only be tested if the computation results are visible to tests
- Prefer pure functions where possible. Pure functions’ return values are determined only by their input parameters.
- Where pure functions aren’t possible, choose immutable objects. The state of immutable objects is determined when the object is constructed and never changes afterwards.
- Avoid writing code that explicitly depends on (or changes) the state of dependencies more than one level deep. Instead, design dependencies, so they encapsulate entirely their next-level-down dependencies
- avoid getter/setter for objects, move any behaviour that uses getter/setter into the objects
Testable Libraries
- 3rd party code doesn’t always have easily visible behaviour. It also introduces breaking API changes with new releases or simply stops being maintained.
- Wrap third-party code in the code that you control.
- Write the wrapper’s API to match the needs of your application, not the third-party code, and add methods as needed to provide easily visible behaviour. This typically involves writing query methods to expose deeply-buries state in terms of the domain that your application needs.
- When the third-party code introduces a breaking change, or needs to be replaced, modify the wrapper, so no other code is affected.
- Frameworks and libraries with sprawling API(s) are more difficult to wrap, so prefer libraries that have a narrowly-defined purpose and a simple API
If the third-party code interfaces with an external system, use an Infrastructure Wrapper.
Infrastructure wrappers
- for each external system - service, database, file system, or even environment variables, create one wrapper class responsible for interfacing with that system.
- Design your wrappers to provide a crisp, clean view of the messy outside world.
- Design your infrastructure classes to stand alone in whatever format is most beneficial to the Logic and Application layers.
focused integration tests
- test your external communication against a production-like environment. For file system code, check that it reads and writes actual files. For databases and services, access an entire database or service.
- Run your focused integration tests against test systems that are reserved exclusively for one machine’s use. It’s best to run locally on your development machine and start and stopped your test or build script. If you share test systems with other developers, you’ll experience unpredictable test failures when multiple people run the test simultaneously.
- Use a spy server when you can’t integrate it into the external system.
Fake it once you make it
- some high-level infrastructure classes depend on low-level infrastructure.
- For tests that check if external communication is done correctly, use a focused integration test (and possibly a spy server).
- For parsing and processing, use more direct and faster nullable infrastructure dependencies.
Paranoic telemetry
- external systems are unreliable. The only sure thing is their eventual failure.
- Test that every failure case either logs an error or sends an alert. Also, test for the requests that hang too.
- Whenever possible, use testable libraries/adapters rather than external services
Zero impact instantiation
- overlapping sociable tests could instantiate a web of dependencies that take too long or cause - side effects. The tests could be slow, difficult to set up or fail unpredictably
- don’t do significant work in the constructor.
- Don’t connect to external systems, start services, or perform long calculations.
- For code that needs to connect to an external system or start a service, provide a connect or start() method.
- For the need to perform a long calculation, consider lazy initialization.
Parameterless instantiation
- ensures that all logic classes can be constructed without providing any parameters (without using a DI framework).
- In practice, this means that most objects instantiate their dependencies in their constructor by default, although they may also accept them as optional parameters.
- If parameterless constructor won’t make any sense, provide a test-only factory method. The factory method should provide overridable defaults for mandatory parameters.
The factory method is easiest to maintain if it’s located next to the actual constructors in the production code. It should be marked as test-specific and straightforward enough to not need tests of its own.
Collaborator-Based Isolation
- call dependencies’ methods to help define test expectations.
- For example, if you’re testing an InventoryReport that includes an address in its header, don’t hardcode “123 Main St.” as your expectation for the report header test. Instead, call Address. renderAsOneLine() as part of defining your test expectation.
- collaborator-based isolation allows you to change features without modifying a lot of tests.
embedded stub
- used to provide nullable infrastructure for tests and avoid duplicating the null checks all over the place.
- Stub out the third-party library that performs external communication rather than changing your infrastructure code.
- Put the stub in the same file as your infrastructure code, so it’s easy to remember and update when your infrastructure code changes.
signature shielding
- to avoid changing method signatures when you refactor the application
- First, encapsulate the methods with proxy or factory methods. Then, program the proxies and factories, so their parameters are all optional.
configurable response
- allow infrastructure methods’ responses to be configured with an optional “responses” parameter to the Nullable Infrastructure’s createNull() factory.
const loginClient = LoginClient.createNull(
validateLogin: { // configure the validateLogin response
email: "my_authenticated_email",
emailVerified: true,
}
);Send State
- application and high-level infrastructure code use their infrastructure dependencies to send data to external systems. They need a way of checking that the data was sent.
- For infrastructure methods that send data and provide a way to observe that data was sent, use domain-oriented observability. Prefer using observer patterns like Send Events.
- If you need more than one send result or can’t store the transmitted data, use “Send Events” To test code that uses infrastructure to get data, use Configurable Responses. To test code that responds to infrastructure events uses “Behavior Simulation.”.
Send Events
- when you test code that uses infrastructure dependencies to send large blobs of data or sends data multiple times in a row. “Send State” will consume too much memory.
- Use an observer pattern to emit an event when your infrastructure code sends data. Include data as part of the event payload.
- When tests need to assert the sent data, they can listen for the events.
- Create a helper function that listens for sent events and stores their data in an array to make your tests easier to read.
Behaviour simulation
- some external systems will push data to you rather than waiting for you to ask for it.
- Therefore, your application and high-level infrastructure code need a way to test what happens when their infrastructure dependencies generate those events.
- Add methods to your infrastructure code that simulate receiving an event from an external system. Share as much code as possible with the code that handles actual external events while remaining convenient for tests to use.
Quotes
“make asynchronous tests detect success as quickly as possible so that they provide rapid feedback”
“test doubles are fine, but don’t stop there if you can invert the dependency and turn expectations into stubs… or even better, replace the stub with the value it returns.”
References
- https://www.jamesshore.com/v2/blog/2018/testing-without-mocks
- https://www.youtube.com/watch?v=mkQ-RvErLiU&ab_channel=TheLegacyofSoCraTes
- https://martinfowler.com/articles/domain-oriented-observability.html
- http://www.growing-object-oriented-software.com/code.html
- practical testing pyramid
- agile testing condensed
- mocks aresn’t stubs